Core concepts
Coverage-guided fuzzing
The dynamic instrumentation that a closed-source binary requires can be generated using DynamoRIO. Also, pe-afl or syzygy can be used for static instrumentation. But these projects are designed for application's instrumentation not a kernel. So we started looking for a project that can measure the coverage of Windows kernel.
A few days later, we found kAFL that uses Intel PT technology and decided to modify it to support Windows driver.
QEMU is possible to create multiple hardware-supported virtual machines (VMs) on a single logical CPU through Intel’s hardware virtualization technology, Intel VT-x. In this case, each VM has a set of its own vCPUs and Intel Processor Tracing(Intel PT) allows you to trace the execution flow of it. So we can get all the execution flow of QEMU's guest and also Windows kernel.
Fuzzing a Windows driver
Even if it is possible to measure the coverage of the Window driver, there's a lot of challenges to solve.
-
Lack of information about IOCTL interface.
If we don't know about IOCTL interface like I/O control codes and
InputBufferLengthin advance, performance of fuzzing will drop dramatically.→ IREC can recover all the details of IOCTL interface. Then, IRPT mutates and generates test cases based on this interface.
-
Difficult to collect interesting seeds.
An application will communicates with Windows driver via
DeviceIoControlfunction. If you want to trace all about communication, it needs to hook IOCTL dispatcher function.→ IRCAP can capture all IRP packets and store them by serialized format. Then, IRPT parses and uses it as an initial test case.
-
The previous IRP request may affect the next due to global variables, lock, mutex or etc. We call these types of problems IOCTL Dependency (or dependency). To solve the dependency problem, We searched for existing studies, but we couldn't find any related materials. Therefore, we had to research and develop a framework ourselves that could flexibly respond to these problems. The below section describes the internal of the framework and how to solve the dependency completely.
Components of IRPT

Corpus database and sends mutated test case to Hypervisor via shared memory. The hypervisor measures its coverage and checks if new coverage or crash has been found. If the new coverage has been found, Optimizer verifies that a new coverage is measured again and sends to corpus database after minimization. If a crash is detected, Reproducer verifies that the crash occurs again and saves it as a file.
Hypervisor
The hypervisor runs QEMU which emulates Windows kernel and kvm (Kernel-based Virtual Machine). While the QEMU emulates an agent which actually communicates with Windows kernel, the kvm traces execution flow of kernel.
How to communicate with Fuzzer
1# common/qemu.py
2class qemu:
3 def __init__(self, qid, config, debug_mode=False, notifiers=True):
4 ...
5 self.cmd += ...
6 " -chardev socket,server,nowait,path=" + self.control_filename + \
7 ",id=irpt_interface " + \
8 "-device irpt,chardev=irpt_interface" + \
When the fuzzer starts QEMU, It can create a socket that communicates with QEMU by specifying the chardev option. The fuzzer sends a byte character to this socket whenever it wants to call a specific operation of the QEMU. When the QEMU receives a byte from the fuzzer, irpt_guest_receive function below is invoked.
1// pt/interface.c
2static void irpt_guest_receive(void *opaque, const uint8_t * buf, int size){
3 kafl_mem_state *s = opaque;
4 for(int i = 0; i < size; i++){
5 switch(buf[i]){
6 case KAFL_PROTO_RELEASE:
7 synchronization_unlock();
8 break;
9
10 ...
11 case KAFL_PROTO_FINALIZE:
12 synchronization_disable_pt(qemu_get_cpu(0));
13 send_char('F', s);
14 break;
15 ...
16}
It is possible to send a byte to the fuzzer by send_char function, but it is usually used to notify if the requested operation did well.
Shared memory
1// pt/interface.c
2static void pci_kafl_guest_realize(DeviceState *dev, Error **errp){
3 ...
4
5 if (s->data_bar_fd_0 != NULL)
6 kafl_guest_create_memory_bar(s, 1, PROGRAM_SIZE, s->data_bar_fd_0, errp);
7 if (s->data_bar_fd_1 != NULL)
8 kafl_guest_create_memory_bar(s, 2, PAYLOAD_SIZE, s->data_bar_fd_1, errp);
9 ...
10}
11
12...
13static Property kafl_guest_properties[] = {
14 DEFINE_PROP_CHR("chardev", kafl_mem_state, chr),
15 DEFINE_PROP_STRING("shm0", kafl_mem_state, data_bar_fd_0),
16 DEFINE_PROP_STRING("shm1", kafl_mem_state, data_bar_fd_1),
17 DEFINE_PROP_STRING("bitmap", kafl_mem_state, bitmap_file),
18 DEFINE_PROP_STRING("coverage_map", kafl_mem_state, coverage_map_file),
19 ...
20 DEFINE_PROP_END_OF_LIST(),
21};
QEMU creates shared memories to send and receive large data.
There are the four shared memories:
shm0: to receive a data contains agent and driver binary.shm1: to receive serialized IRP requests.bitmap: used to check thatprogramreaches the new execution path.coverage_map: used to track the execution flow ofprogram.
A detailed description of these shared memories is described later sections.
write_virtual_memory, read_virtual_memory
1// pt/memory_access.h
2bool read_virtual_memory(uint64_t address, uint8_t* data, uint32_t size, CPUState *cpu);
3bool write_virtual_memory(uint64_t address, uint8_t* data, uint32_t size, CPUState *cpu);
It can access any virtual memory on guest even a kernel space. QEMU uses these functions and shared memory to deliver a data received from the fuzzer to agent.
Agent
It first registers the target driver as a service. And it loads and opens the device, which calls DeviceIoControl function or other command sent from fuzzer.
How to communicate with Hypervisor
1// kafl_user.h
2static void kAFL_hypercall(uint64_t rbx, uint64_t rcx){
3 uint64_t rax = HYPERCALL_KAFL_RAX_ID;
4 asm volatile("movq %0, %%rcx;"
5 "movq %1, %%rbx;"
6 "movq %2, %%rax;"
7 "vmcall"
8 :
9 : "r" (rcx), "r" (rbx), "r" (rax)
10 : "rax", "rcx", "rbx"
11 );
12}
1// agent.cpp
2...
3int main(int argc, char** argv){
4 /* submit the guest virtual address of the payload buffer */
5 hprintf("[+] Submitting buffer address to hypervisor...");
6 kAFL_hypercall(HYPERCALL_KAFL_GET_PAYLOAD, (UINT64)payload_buffer);
7 ...
8}
When the agent wants to communicate with the hypervisor(QEMU) directly, it requests the hypercall with the syscall number and arguments. Then, QEMU process the hypercall according to the syscall number.
Anti IOCTL filter

GetCurrentProcessId and GetCurrentThreadId function.
1// target/src/agent.cpp
2...
3case ANTI_IOCTL_FILTER:
4 psGetCurrentProcessId = resolve_KernelFunction(sPsGetCurrentProcessId);
5 psGetCurrentThreadId = resolve_KernelFunction(sPsGetCurrentThreadId);
6
7 *(uint32_t*)(ioctl_filter_bypass + 1) = GetCurrentProcessId();
8 kAFL_hypercallEx(HYPERCALL_KAFL_MEMWRITE, psGetCurrentProcessId + 0x10, (uint64_t)ioctl_filter_bypass, sizeof(ioctl_filter_bypass));
9 *(uint32_t*)(ioctl_filter_bypass + 1) = GetCurrentThreadId();
10 kAFL_hypercallEx(HYPERCALL_KAFL_MEMWRITE, psGetCurrentThreadId + 0x10, (uint64_t)ioctl_filter_bypass, sizeof(ioctl_filter_bypass));
11 break;
12 }
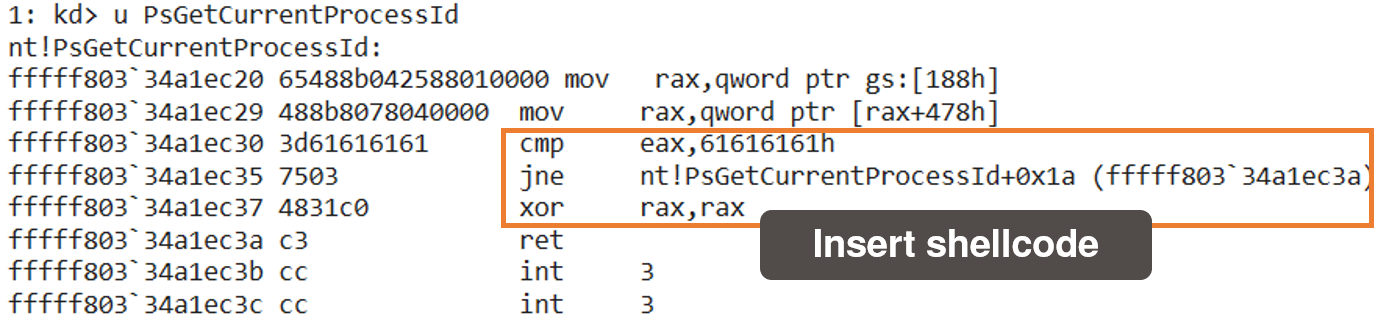
write_virtual_memory function. The patched function returns only zero if the current process ID is the same as the agent's ID.
IRP Program

IRP Program is a basic unit of all components of IRPT. It contains several IRP classes corresponding to DeviceIoControl call. The reason why we use this structure as a unit is to solve the following problems. We will call it program from now on.
Dependency reset
To avoid previous IRP request, we have to reload a driver at a certain point.
1# fuzzer/process/process.py
2 def execute(self, program):
3 self.__set_current_program_with_count(program)
4 self.q.reload_driver() # reload!
5
6 for i in range(len(self.cur_program.irps)):
7 if self.execute_irp(i):
8 return True
1def _revert_driver(self):
2 try:
3 self.send_irp(IRP(0, 0, 0, command=qemu_protocol.DRIVER_REVERT))
4 except ConnectionResetError:
5 sys.exit()
6
7def _reload_driver(self):
8 self.send_irp(IRP(0, 0, 0, command=qemu_protocol.DRIVER_RELOAD))
IRPT reloads a target driver in every execution of program via qemu._reload_driver function. For the target driver can't reload manually, we provide revert option. However, this option is experimental and unstable for some drivers.
1void handle_hypercall_irpt_ip_filtering(struct kvm_run *run, CPUState *cpu) {
2 ...
3 if (start && end) {
4 uint64_t start = run->hypercall.args[0];
5 uint64_t end = run->hypercall.args[1];
6 ...
7
8 read_virtual_memory(driver_info.imagebase, driver_info.image, driver_info.imagesize , cpu);
9 pt_enable_ip_filtering(cpu, filter_id, start, end, false);
10 return;
11 }
12 // Revert mode
13 write_virtual_memory(driver_info.imagebase, driver_info.image, driver_info.imagesize , cpu);
14 }
15}
It just copies the entire image of the target driver right after the driver is loaded. And pastes it when the dependency reset is needed.
Order dependency
If we operate the fuzzing process with program, the fuzzer can recognize the order of the IRP requests.
1# wdm/program.py
2class Program:
3 ...
4 def mutate(self, corpus_programs):
5 ...
6 if rand.oneOf(5) and self.__splice(corpus_programs):
7 method = "splice"
8 elif rand.oneOf(10) and self.__swapIRP():
9 method = "swapIRP"
10 elif rand.oneOf(10) and self.__insertIRP(corpus_programs):
11 method = "insertIRP"
12 elif rand.oneOf(20) and self.__removeIRP():
13 method = "removeIRP"
14
15 self.set_state(method)
16 return method
The mutation of the order allows fuzzer to know which order is interesting. Details of mutation algorithm is described in the following sections.
Mutator
The mutator is designed to generate various types of IRP. We will continue to discuss and develop mutation strategies reflecting characteristics of the Windows driver.
There are three main categories of mutation.
1. Program mutation
It is used to mutate structure of program and divided into four sub routines below. Each routine has a random probability.
splice : Merges with random IRP Program. (about 5%)
swapIRP : Swap the location of two IRP. (about 9.5%)
insertIRP : Insert IRP at the random location. (about 8.55%)
removeIRP : Remove IRP at the random location. (about 15.39%)
2. deterministic
Most of its strategies come from afl's deterministic. When the program goes through fuzzing steps at first, and tweaks to some regions in the IRP are observed to have effect on the execution path, except in these two cases maybe excluded from deterministic logic - and the fuzzer may proceed straight to havoc.
The deterministic strategies include below and most of them tweak InputBuffer of IRP:
Walking bit and byte flips : Sequential bit and byte flips with varying lengths and stepovers (Same as afl)
Simple arithmetics : Sequential addition and subtraction of small integers (Same as afl)
Known integers : Sequential insertion of known interesting integers (Same as afl)
One day : Interesting edge cases only can occur in IOCTL.
3. havoc
As you know, deterministic strategies are not exhaustive. havoc calculates a more diverse and random value reflecting the characteristics of IOCTL communication.
1# fuzzer/technique/havoc.py
2def mutate_seq_8_bit_rand8bit(self, index):
3 ...
4 for _ in range(32):
5 value = in_range_8(rand.Intn(0xff))
6 if (is_not_bitflip(orig ^ value) and
7 is_not_arithmetic(orig, value, 1) and
8 is_not_interesting(orig, value, 1, 1)):
9 data[i] = value
10 if self.execute_irp(index):
11 return True
Check if it can be made by deterministic strategies before sending to agent, so duplicated test cases are not executed.
T
he havoc strategies include below:
Walking random bytes insertion : Sequential random bytes insertion with varying lengths.
Random integers : Sequential insertion of random integers.
Random buffer length : Insertion of random InputBufferLength and OutputBufferLength.
Bruteforce IRP requests : Send a random program many times.
Optimizer
It validates a mutated test case once again and leaves only the programs that affect the new coverage.
Validation
1# wdm/optimizer.py
2def optimize(self):
3 ...
4 # quick validation.
5 self.q.turn_on_coverage_map()
6 new_res = self.__execute(program.irps)
7 self.q.turn_off_coverage_map()
8 if not new_res:
9 continue
10
11 old_array = old_res.copy_to_array()
12 new_array = new_res.copy_to_array()
13 if new_array != old_array:
14 continue
The Intel PT trace consists of a sequence of packets and FUP (Flow Update Packet) for asynchronous event. Even if the program has no effect on the execution path, the bitmap can be different due to FUP. So the optimizer compares original bitmap with the newly calculated bitmap.
Minization
1# wdm/optimizer.py
2def optimize(self):
3 ...
4 while i < len(program.irps) and len(program.irps) > 1:
5 exec_res = self.__execute(program.irps[:i] + program.irps[i+1:])
6 if not exec_res:
7 continue
8
9 dependent = False
10 for index in new_bytes.keys():
11 if exec_res.cbuffer[index] != new_bytes[index]:
12 dependent = True
13 break
14 if not dependent:
15 for index in new_bits.keys():
16 if exec_res.cbuffer[index] != new_bits[index]:
17 dependent = True
18 break
19 if not dependent:
20 del program.irps[i]
21 else:
22 i += 1
After validation, the optimizer minimizes a mutated program by removing non-dependent IRP. (dependent meaning it effects on the new execution path)
Corpus database
The number of programs will be increased gradually as the fuzzer continues to run. Some of them may have duplicated coverage or won't need to mutate anymore.
coverage map
1void pt_bitmap(uint64_t addr){
2 ...
3 if(bitmap){
4 addr -= module_base_address;
5 if (is_coveraged && coverage_map) {
6 coverage_map[addr % (kafl_coverage_map_size/sizeof(uint16_t))] = ++coverage_id;
7 }
8 ...
9 bitmap[transition_value & (kafl_bitmap_size-1)]++;
10 }
11 last_ip = addr;
12}
We use a coverage_map containing execution flow of the program to determine if two programs has the same coverage.
1def turn_on_coverage_map(self):
2 self.__debug_send(qemu_protocol.COVERAGE_ON)
3
4def turn_off_coverage_map(self):
5 self.__debug_send(qemu_protocol.COVERAGE_OFF)
To avoid performance bottleneck, perform related operations only after calling the turn_on_coverage_map function.
Deduplication
The corpus database has two groups of the program, programs and unique_programs. unique_programs is a group that has unique execution flows.
1# wdm/database.py
2def __unique_selection(self, new_programs):
3 ...
4 for new_program in new_programs:
5 new_coverage_set = set(new_program.coverage_map)
6
7 # Remove a duplicated unique program.
8 i = 0
9 while i < len(self.unique_programs):
10 old_coverage_set = set(self.unique_programs[i].coverage_map)
11
12 count = 0
13 for address in new_coverage_set:
14 if address in old_coverage_set:
15 count += 1
16
17 if len(old_coverage_set) == count:
18 del self.unique_programs[i]
19 else:
20 i += 1
21 self.unique_programs.append(new_program)
The __unique_selection function is invoked when a new interesting program finished optimizing. It keeps group to have only unique programs using coverage_map.
Scoring
In order to prioritize unique programs, we compute probability map with depth of mutation(level), number of executions(exec_count) and number of code blocks executed.
1# wdm/database.py
2def update_probability_map(self):
3 ...
4 for uniq_program in self.unique_programs:
5 score = REMOVE_THRESHOLD
6 score += uniq_program.get_level() * 20
7 score += len(set(uniq_program.coverage_map)) * 2
8 score -= uniq_program.get_exec_count() * 20
9 score = max(score, 1)
10
11 total_score += score
12 self.probability_map.append(score)
13
14 for i, uniq_program in enumerate(self.unique_programs):
15 self.probability_map[i] /= total_score
16...
17def get_next(self):
18 if len(self.unique_programs) == 0 or rand.oneOf(10):
19 program = random.choice(self.programs)
20 else:
21 program = np.random.choice(self.unique_programs, p=self.probability_map)
22 return program
We should continue to find the optimal probability equation.
Reproducer
It is responsible for crash reproduction. Because, we run the Windows kernel under the QEMU, occasionally encounters errors and stops while communicating with the fuzzer. So we should have to validate crashing test case once again.
De-duping crashes
1# wdm/reproducer.py
2def reproduce(self):
3 ...
4 for i in range(len(program.irps)):
5 exec_res = self.q.send_irp(program.irps[i])
6
7 if exec_res.is_crash():
8 log("[*] %s found!!" % exec_res.exit_reason, "CRASH")
9 ...
10
11 unique = False
12 for address in exec_res.coverage_to_array():
13 if address not in self.crash_map:
14 unique = True
15 self.crash_map[address] = True
The crash_map has all the listing of the crashing programs' block addresses. If the listing of the newly found crashing programs' addresses contain an address that is not included in crash_map, it is classified as a unique crash.